Other
- Juliana Fonseca Paim (Unlicensed)
- Joanna Huddleston
Script Models
Supervised Script Model
Create a Supervised Script Model
The parameters for this method are defined on two tabs at the top of the page: Properties and Advanced.
On the Properties tab:
Enter a Name for your model.
Select a Learning set from the list.
Select a Testing set from the list.
Enter a Predict variable name and an Error variable name.
Select Variable Set, if required.
Select variable(s) from the list for the Inputs.
Select a variable for the Output.
Click Save to generate the Model quality, Model accuracy report tabs.
On the Advanced tab:
Select the script Language. Options: Javascript, Python and Common Lisp.
Write the script.
Script Model
Create a Script Model
The parameters for this method are defined on two tabs at the top of the page: Properties, Script and Advanced.
On the Properties tab:
Enter script model Name.
Select Variable Set, if required.
Select variable(s) from the list for the Inputs.
Enter the Output variables of the script model. Select Type. If required, add Title and Unit. Click on +ADD to add several outputs.
On the Script tab:
Select the script Language. Options: Javascript, Python and Common Lisp.
Write the script.
On the Advanced tab:
Select Input tasks.
For more information, see the online learning platform
Usable for Function variables and supervised models (LR, KNN, ANN, DT, ET, MART, Adaboost, PLS, Supervised Script Model).
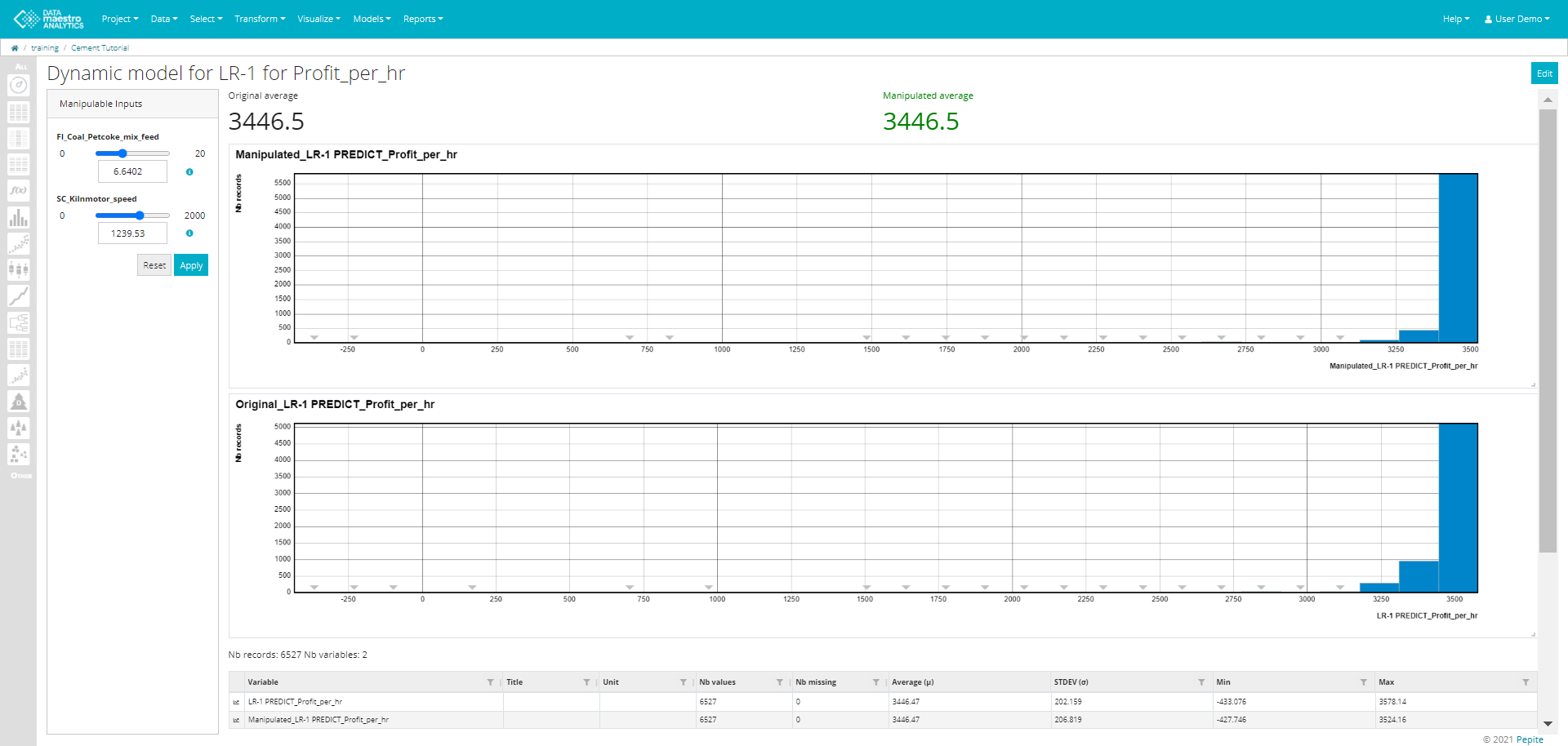
Create a Dynamic Model
- Enter a Title. Note that this field is automatically filled out once the function variable/model is selected. Example: Dynamic model for Linear Regression.
Enter a Manipulated variable name. Note that this field is automatically filled out once the function variable/model is selected. Example: NEW_Linear Regression.
Select a Function variable / Model.
Once the function or model is selected a list of Manipulable Inputs used for the function/ model appears. Select the Manipulable Inputs from the list.
Select Target. Options: Maximization or Minimization.
- Select and Record Set, if required.
- Click Save.
Partial Dependence Plots
Partial Dependence Plots (PDP) are a useful visualization tool to help interpret the results of predictive machine learning models, specifically how each input influences the output variable. This tool varies each input variable one-by-one keeping all other input variables equal to historical data and calculates the new predicted values.
Enter Title.
Select Record Set. Define the record set to be used for calculating the predicted values.
Define record set
This does not necessarily need to correspond with the Learning or Testing set used for model development, however, to avoid significant extrapolation, it is best to remain with a cleaned set of records.
Select Model. Currently PDPs can be calculated for all Regression supervised learning methods, with at least one numerical input.
- Choose X Range. This is the range within which each input variable will be tested. There are two options:
- Data set min/max = The range will correspond to the min and max values for the given variable for the specified record set.
- 𝞵 ± N * σ = The range will correspond to Mean plus or minus N x Standard Deviation for the given variable for the specified record set.
- Enter a Step. The number of discrete values to be tested within the X Range.
- Select Manipulable variables. Select the variables to be manipulated. All numerical variables can be selected.
On the Advanced tab:
In Scatter Plot:
- Enter Conditional Class Count. For more information, see Conditional Class Count.
- Select Legend Position. Options: Default and None.
- In Histogram:
- Enter Conditional Class Count. For more information, see Conditional Class Count.
- Select Legend Position. Options: Default and None.
For each manipulable variable:
- For each step i for the given range:
a. Set the training data as the historical values and replace the historical values of 𝑥1 with the constant 𝑥1i.
b. Compute the predicted values for the given record set data.
c. Plot the values on the scatter plot for 𝑥1 versus predictions.
2. The colors on the scatter plot indicate data density (or number of records).
3. The ”mean” black line, indicates the average for all predictions displayed.
4. The histogram shows the original distribution of the manipulable variable versus the model output.
5. Click Next Variable to see the results from the next selected manipulable variable.
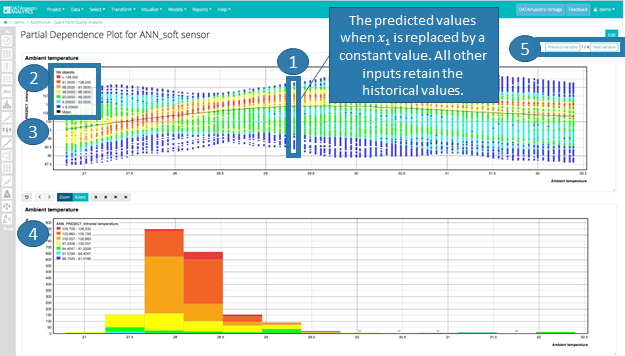
In the example below, Ambient temperature has been varied with a step = 100. For each step, the full record set is used to compute the different predicted values for the output ANN_Soft Sensor.
Based on the scatter plot, there appears to be a parabolic relationship between ambient temperature and the output.
Looking at the histogram, however, as most data is below 30, interpretation is limited beyond this value.
If Zoom, it recalculates step
Sensitivity Analysis
Sensitivity Analysis is a useful visualization tool to help interpret the results of predictive machine learning models, specifically how variations in each input influence the predicted output.
Find it under Models / Other / Sensitivity Analysis.
On Properties tab:
Enter Title.
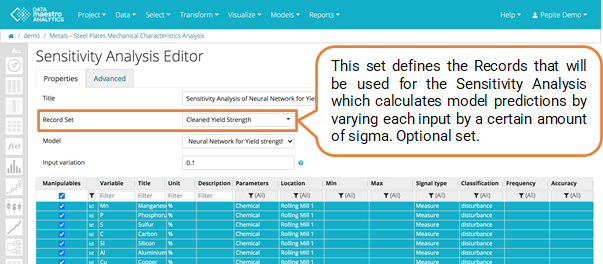
Select Record Set.
- Select a Model, all models created in the project are presented at a list.
- Select the Manipulable variables.
- Enter Input variation that is the variation applied on each input. For a Input variation equals to 0.1, each input = 0.1* 6 * sigma.
On Advanced tab:
Enter Output Type. There are two types of output:
Normalized : Result = f(x + d) - f(x) / (6 * σ )
Absolute: Result = f(x + d) - f(x)With f(x) = predicted value for one row of the dataset, f(x + d) = predicted value for one row of the dataset with an increment on one input, σ : standard deviation of predicted value on whole unmodified dataset.
Output Type
By default the output variation is normalized before drawing the boxplot. In that case, all output variations are divided by six sigma of the output value in the initial datasource.User can also choose to use absolute values of output variations.
- Enter Font Size.
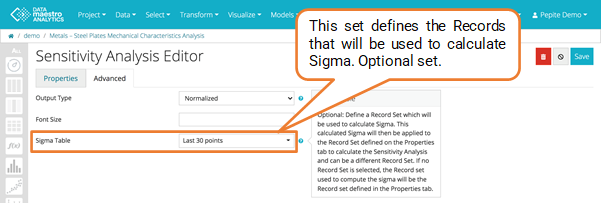
- Select a record set in Sigma table (Optional). Define a Record Set which will be used to calculate Sigma. This calculated Sigma will then be applied to the Record Set defined on the Properties tab to calculate the Sensitivity Analysis and can be a different Record Set. If no Record Set is selectionned, the Record set used to compute the sigma will be the Record set defined in the Properties tab.
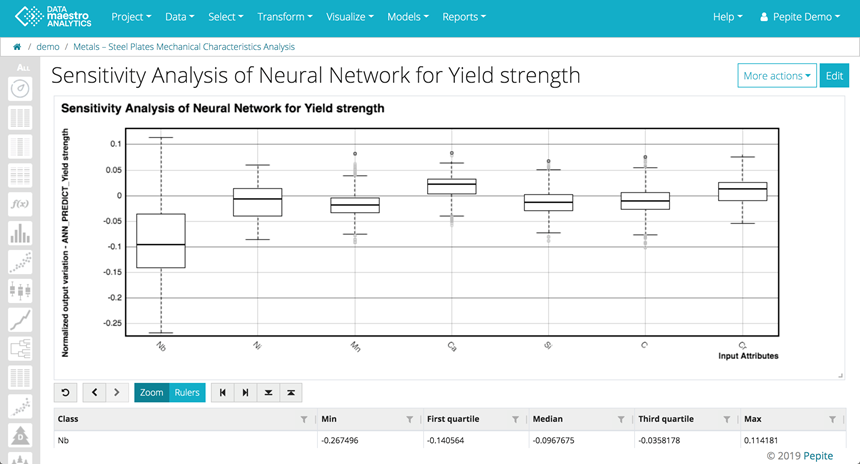
The sensitivity analysis shows how variations in each input can influence the predicted output. In the example below, the box plot shows that the output Yield Strength is influenced by the variable chemical component Niobium (Nb) followed by Nickel (Ni).
The variables are listed in decreasing order based on the First & Third Quartile absolute values.
Sigma table
A Sensitivity Analysis can help you understand and interpret model results.
For improved interpretability, define an optional Record Set for the Sigma calculation.
For example:
- If you have built a model on 12 months of cleaned data.
- Now you want to understand the influence of your different input parameters on your KPI but you want to focus your analysis on the last few days. However, over the last few days, there hasn’t been much variability in your input parameters and therefore Sigma for the last few days is low.
- At “Sigma Table” (Advance Tab), define the “Record Set” for the 12 months of cleaned data. This will calculate a sigma value, used for the Sensitivity Analysis that is representative of your full data set. This set is optional.
- Then at “Record Set” (Properties Tab), select the “Last days” set for your analysis. This set is optional.
Isolation Forest
For more information, see the online learing platform.
An isolation forest, is a visual representation of multiple trees used for anomaly detection. In the DATAmaestro method, data points are split randomly, with anomalies isolated in fewer steps. The depth in the tree indicates the anomaly score, with shorter paths highlighting more abnormal points and therefore potential outliers.
Method principles
Isolation Forest isolates data points by randomly selecting features and split values, subsequently constructing isolation trees. Anomalies tend to have shorter path lengths in the trees, indicating a higher likelihood of being outliers. Path lengths can be relatively short (indicating anomalies) or longer (suggesting regular data points).
Inputs: Must be numerical and highdimensional datasets are particularly suited.
For more information please refer to Wikipedia - Isolation Forest .
On Properties tab:
Go to Models > Isolation Forest in the top menu. Or click the Ensemble tree icon in the left bar.
Enter Model name.
Select at the Learning Set (Record Set). Typically, we want to use a Learning set that defines the process in the state that we want to clean. E.g. Process on and running in stable conditions.
- Enter a Score Variable Name, Isolation forest calculates an anomaly score for each record in the Learning Set. A higher score indicates a potential outlier.
- Select the Filter variables by.
- Select input variables. Tip: It could be a good idea to make a Variable set to select rather than each variable individually. Search and select variable set name in the table of variables. To create a new Variable set, in Analytics, go to Select menu in top menu bar.
- Select a Cond. one or more (Optional). E.g. product type, gauge, rate, … (Symbolic variables) For rate: calculated a symbolic version rate variable (e.g. low, medium, high rate).
- Click Save.
On Advanced tab:
Enter a Seed. The seed for IF determines the randomness in the algorithm’s tree construction. Leave by default.
- Enter a Tree count. Tree count in Isolation Forest specifies the number of trees in the model. Start with 100 and depending on results &/or calculation time, could be increased.
On duration curve:
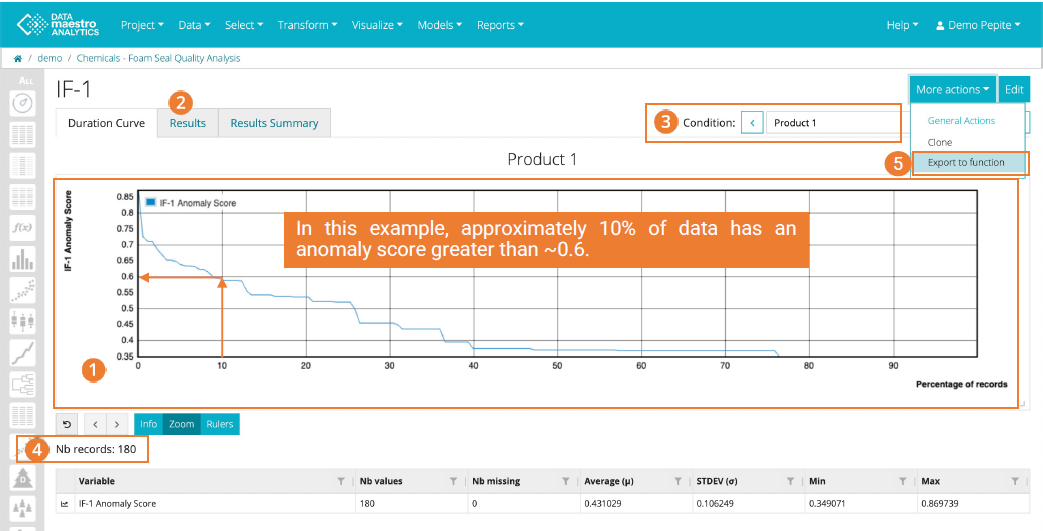
The duration curve, sorted in descending order, visualizes the anomaly scores from the Isolation Forest. Higher scores represents the most abnormal data, providing a quick overview of suspicious data for priority analysis.
- X-axis represent the percentage of data and Yaxis represent the anomaly score.
- Click “Result to view the anomaly score per record.
- If any Conditions were selected, view the Duration curve per Condition. The left and right arrows change the condition.
- See the number of associated records for the current Condition.
- There are several options for using the Isolation score:
- Use the Anomaly Score directly (e.g. in Record Sets or on graphs). Caution: When updating the model, the Anomaly score will change and may no longer be a relevant value.
- Click on More action, Export to function” to set up a Script and keep a fixed Percentage of outliers.
Anomaly score
Depending on the data set, the anomaly score will change.
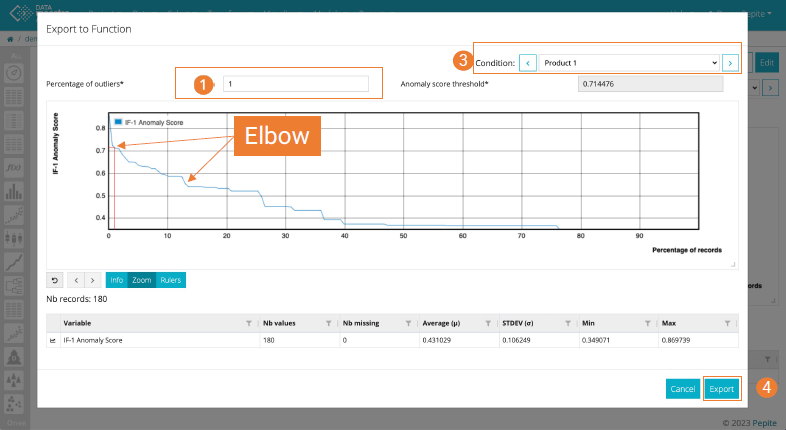
On Export to Function:
To enhance the use of Isolation Forest, it is possible to convert the model output into a script. This facilitates the rapid selection of a specific outlier percentage and visualize of the corresponding anomaly score.
Enter the Percentage of outliers (for the current condition if there are multiple conditions). Next to the Percentage, the corresponding anomaly score threshold is displayed.
Look for an "elbow"
Look for an “elbow” in the curve to choose a percentage of outliers. The “elbow” indicates that there is a larger difference in the points from the other closest points. Also, think about from a process view, how the process has been running and how many percentage of
data points should be seen as outliers.- On the plot, the selected percentage can be visualized.
- If a variable is conditioned, the principle remains the same; however, it is possible to choose a percentage for each condition.
Anomaly score
Depending on the data set, the anomaly score will change.
On script model isolation forest:
- The Script Model Editor will open. Click Save.
- Finally the result of the script model can be used in your analysis or for data cleaning Record Sets.
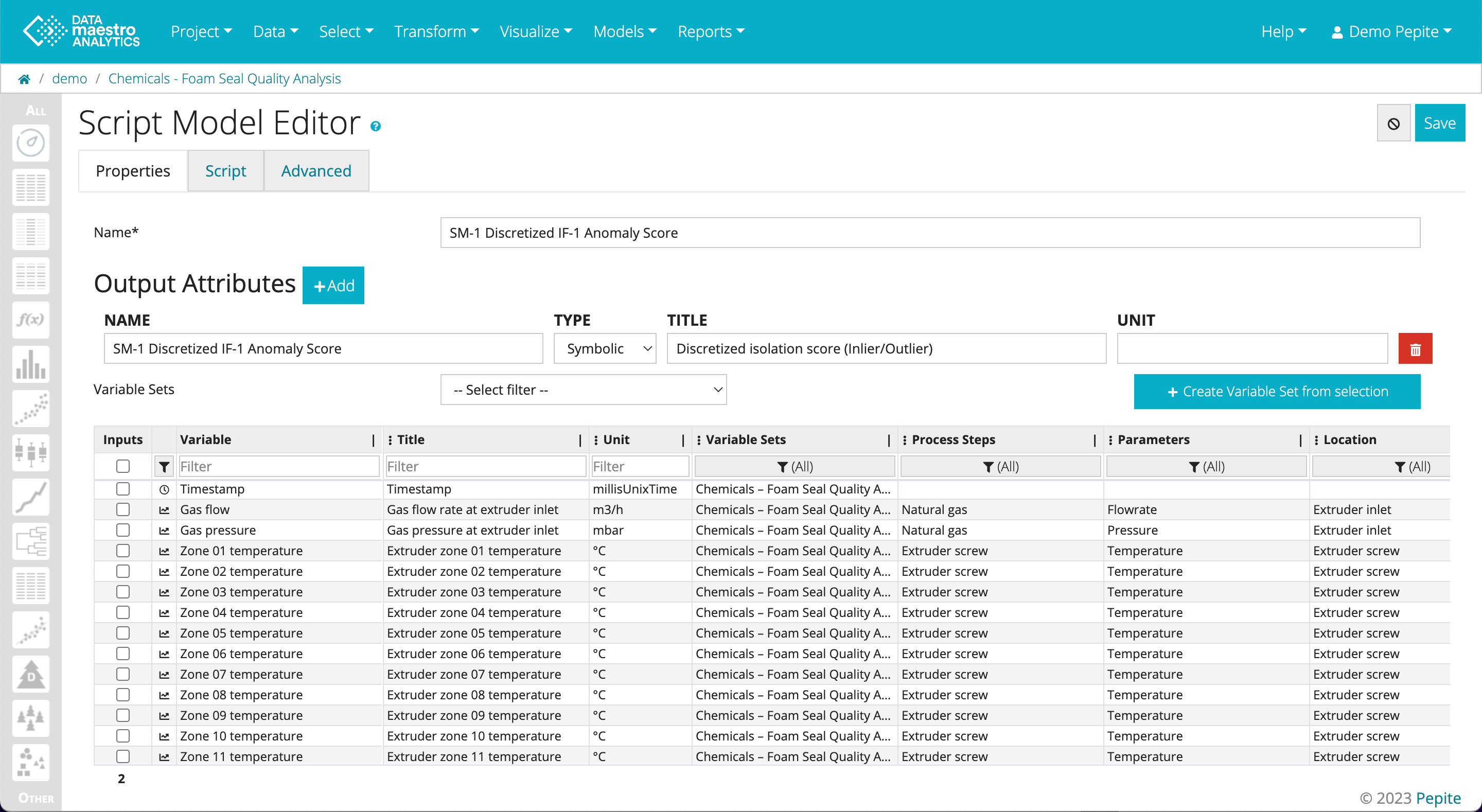
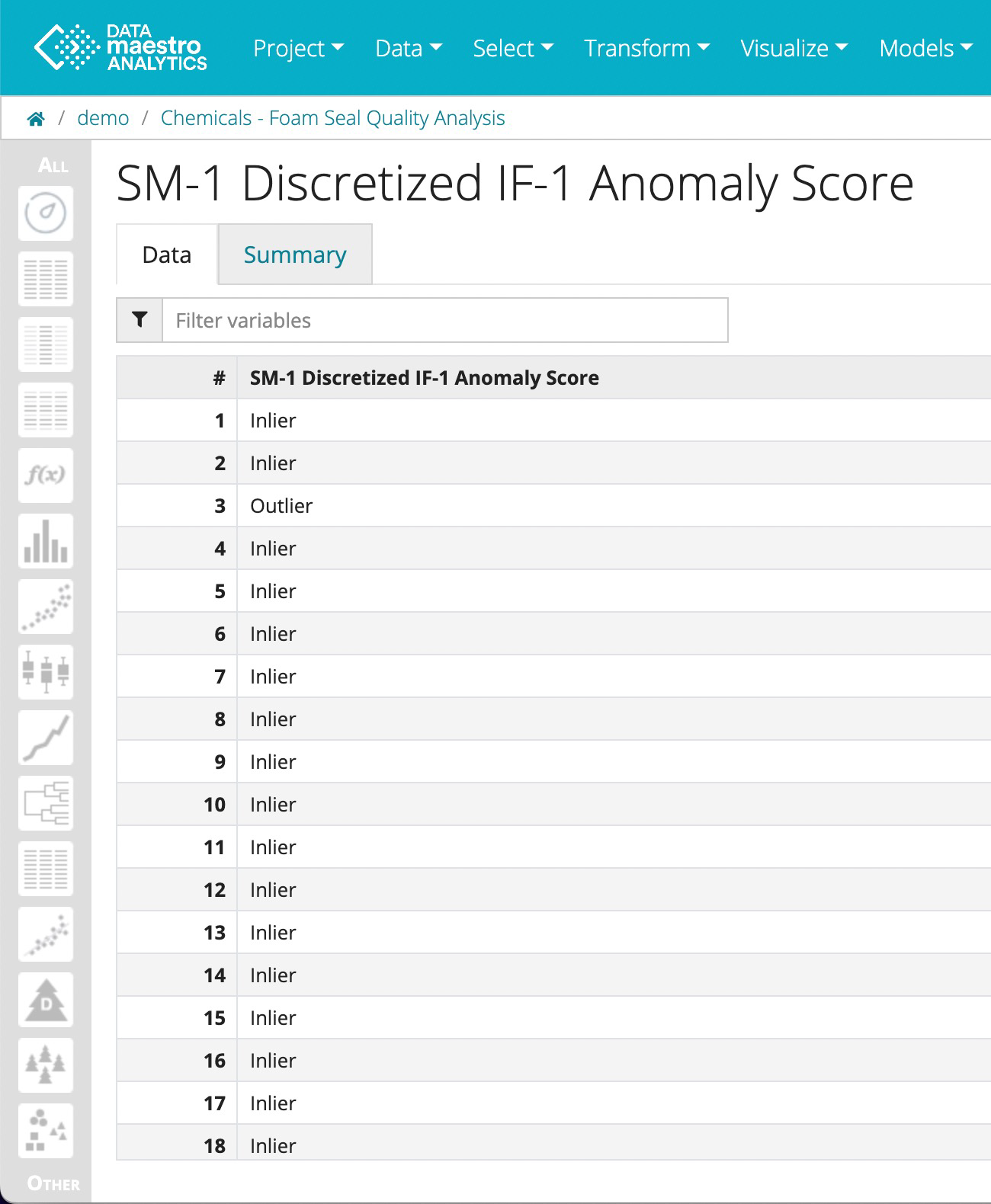
On Principal Component Analysis:
Create a PCA to visualize the Isolation Forest results:
- Learning Set: Use the same Record set as for the Isolation Forest.
- Inputs: Use the same Input Variables as for the Isolation Forest.
- Number of components: Select 2.
- Click Save.
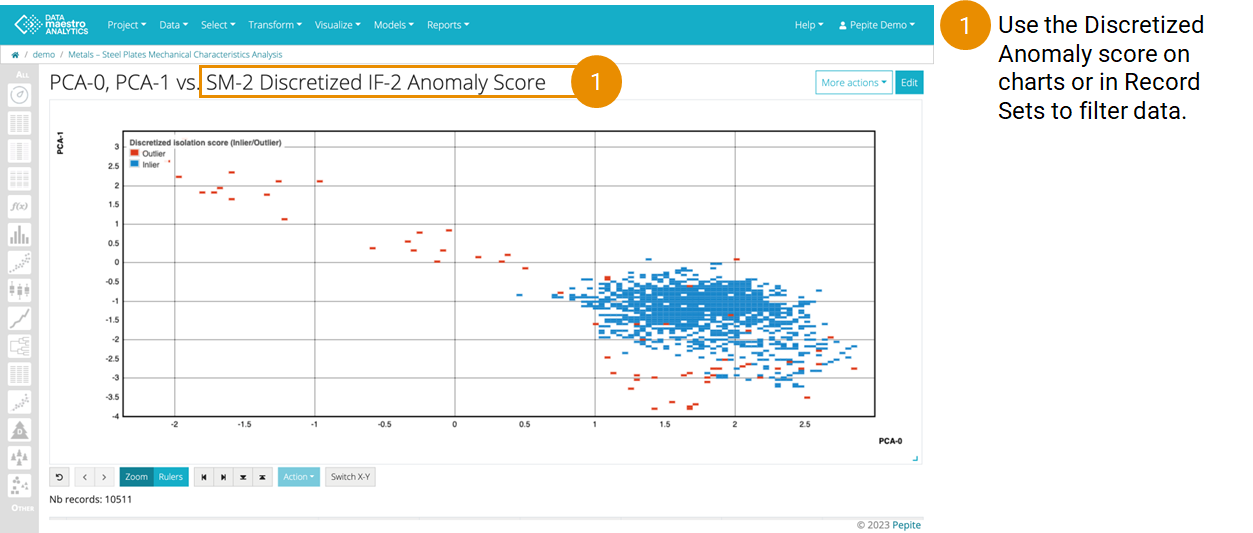
Then create a scatter plot to visualize results:
- Record set: Use the same Record set as for the Isolation Forest and PCA
- X Axis: Select the PCA-0 variable
- Y Axis: Select the PCA-1 variable
- Condition: Select the SM-1 Discretized IF-1 Anomaly Score
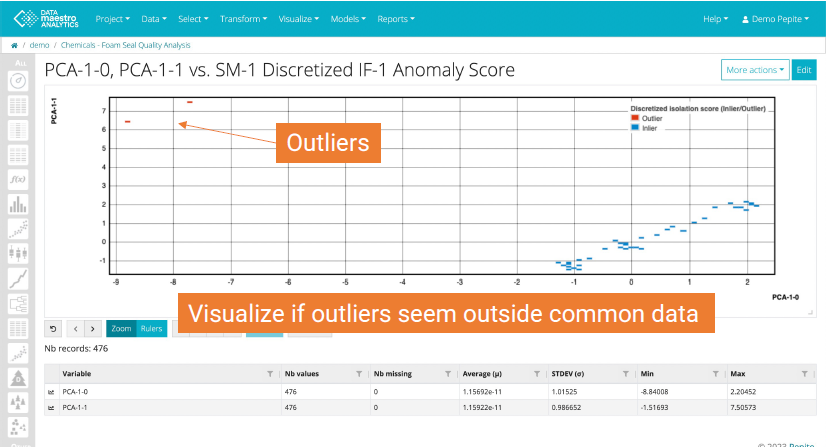
Isolation Forest for data cleaning and outlier detection
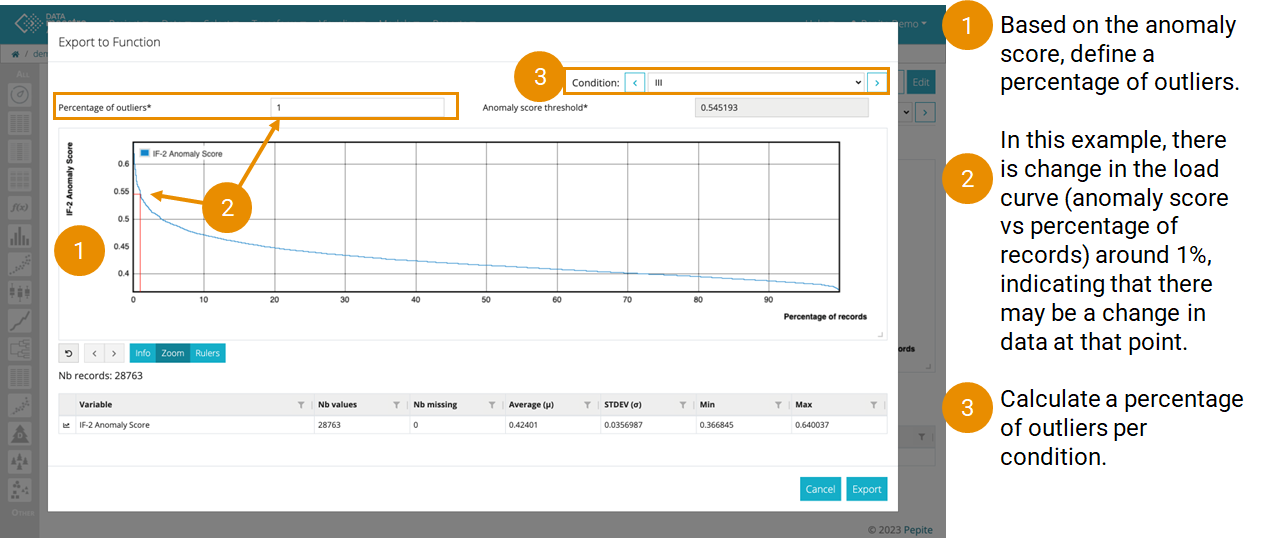
Automatically create a function to label a percentage as outliers
Automatically create a function to label a percentage as outliers
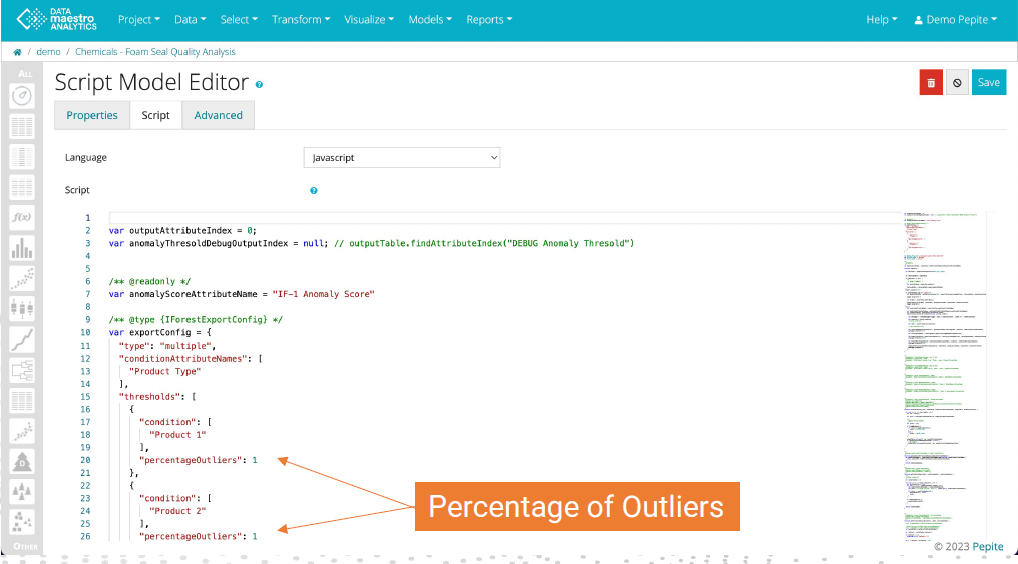
Adapting Percentage of Outliers
To change the Percentage of Outliers, return to the Script Model.
To change Script model:
To change the Percentage of Outliers, return to the Script Model:
- In the Other menu, find the SM-1 Discretized IF-1 Anomaly Score
- Click Edit
- Go to the Script Tab
- Scroll down to locate the“percentageOutliers”. There will be one per condition.
- Enter the new percentage(s)
- Click Save
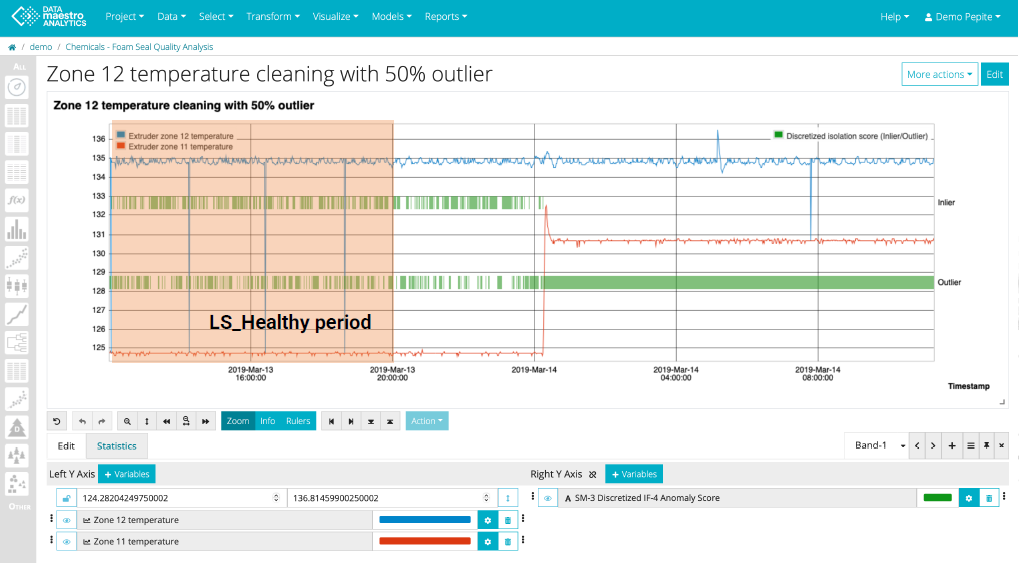
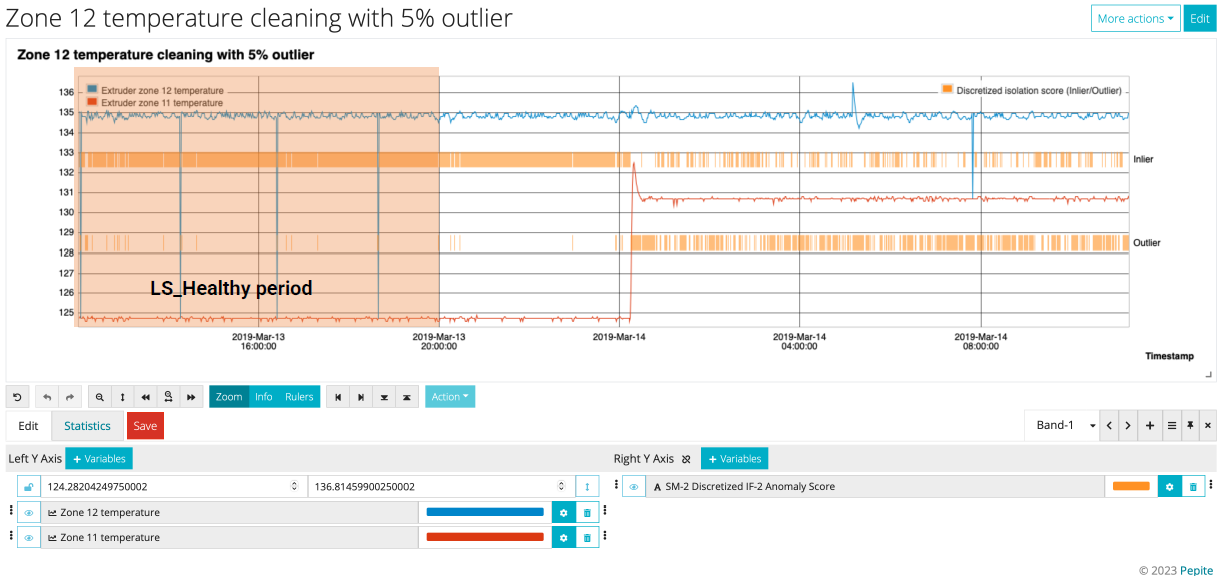
Application (5% outlier):
- Training phase: 5% of data flagged as outliers
- Evaluation on recent data: Noticeable spike in outliers post March 14th
- Possible anomaly period detected
- Consideration: Shift in data nature or model tuning needed?
- Next steps: Manual validation, potential model updates, and further investigation of the anomaly period
Application (50% outlier):
- New training threshold: 50% of data flagged as outliers
- Findings on recent data: Every data point post March 14th is identified as an outlier
- Implication: Significant spike in anomalies or potential model overfitting?
- Next steps: Re-evaluate threshold, manual validation, and model tuning if needed