Machine Automatic learning algorithms are designed to create a model of a complex system from a set of observations or simulations. The model represents relationships between the variables that describe the system. And the goal of the model is to predict the behaviour of the system in some unencountered situations or merely to explain its behaviour. The machine learning methods described below are useful tools to solve a wide range of problems. Each method builds models in the form of new variables, which can be used as inputs for other methods. The ability to reuse models as inputs for other models gives DATAmaestro the power of hybrid approaches, where more than one learning model is used in the analysis process. About ModelsThere are two main types of machine learning algorithms used to build predictive models: unsupervised and supervised. Unsupervised AlgorithmsUnsupervised algorithms are useful when you do not have a specific output variable to explain or predict. Typically, this type of algorithm is used to: Find a correlation or association between variables. For example, what an online shopping site would use to find baskets of goods you buy together. Detect clusters of records that have similar behaviour. For example, an organization of operations that are similar, like energy consumption patterns.
Supervised AlgorithmsSupervised algorithms are useful when you have a value (a variable) that you want to explain (predict or model) with other variables. For example, if you want to predict the fuel consumption in your house with external temperature, air humidity, or time of the day. To run a supervised algorithm: Select a Learning set to train the model. Select a Test set to test the reliability of the model. Select a set of variables as inputs. Identify a variable for the goal (what you try to predict with the inputs). Select the type of problem (R/C/O) and the method. Specify possible learning parameters for the method.
| Info |
|---|
| title | Required Learning and Testing sets |
|---|
| Before you can build a learning model you must have two record sets: one for Learning and for Testing. |
| Info |
|---|
| Certain models in DATAmaestro are able to handle missing values, while other models are not. For example, clustering methods, like K-means, and predictive models, like linear regression are not able to handle missing value. If any row of data has a missing value, even for just one variable, the row will need to be ignored by the algorithm. “Learning set is empty” is the message to indicate that all rows have been removed due to one or more missing values per row by the algorithm. If you have any variables with a high number of missing values, it is recommended to remove them or to use the “Fill missing values” tool under the “Transform” menu in DATAmaestro Analytics. |
What can I do with each Supervised Learning method?
| Algorithm | Classification | Regression | Input variables | Analysis type |
|---|
| Linear Regression | No | Yes | Numerical only | Predictive modelling | | Decision/Regression Tree | Yes | Yes | Numerical & symbolic | Root Cause Analysis Predictive Modelling | | Extra Trees | Yes | Yes | Numerical & symbolic | Root Cause Analysis Predictive Modelling | | Adaboost | Yes | Yes | Numerical & symbolic | Root Cause Analysis Predictive Modelling | MART (Multiple Additive Regression Trees) | No | Yes | Numerical & symbolic | Root Cause Analysis Predictive Modelling | | K-Nearest Neighbors | Yes | Yes | Numerical only | Predictive Modelling | | Partial Least Squares | No | Yes | Numerical only | Predictive Modelling | | Artificial Neural Networks | Yes | Yes | Numerical only | Predictive Modelling |
What can I do with each method?
| Method | Classification | Regression | Input variables | Analysis type |
|---|
| Clustering | NA | NA | Numerical only | Unsupervised
Descriptive Analytics | | Principal Component Analysis | NA | NA | Numerical only | Unsupervised
Descriptive Analytics | | Dendrogram | NA | NA | Numerical only | Correlation unsupervised Descriptive Analytics | | PRIM optimization | Yes | Yes | Numerical & symbolic | Optimization
Prescriptive analytics | | Optimizer | No | Yes | Numerical only | Multi-constraint optimization
Prescriptive analytics | | ISHM (Inductive System Health Monitoring) | NA | NA | Numerical only | Monitoring
Prescriptive analytics | | Statistical Process Control | NA | NA | Numerical only | Monitoring
Prescriptive analytics | Statistical Tests: Welch’s T-Test | Yes | No | Numerical only | Statistical Correlation
Root Cause Analysis | | Statistical Tests: Kruskal Wallis ANOVA) | Yes | No | Numerical only | Statistical Correlation
Root Cause Analysis | Statistical Tests: Pearson (Linear correlations) | No | Yes | Numerical only | Statistical Correlation
Root Cause Analysis | | Statistical Tests: Spearman (Non-linear correlations) | No | Yes | Numerical only | Statistical Correlation
Root Cause Analysis | | Change Point Analysis | NA | NA | Numerical only | Descriptive analysis | Dynamic Model | Yes | Yes | Numerical & symbolic | Root Cause Analysis
Prescriptive analytics | | Sensitivity Analysis | Yes | Yes | Numerical & symbolic | Root Cause Analysis
Prescriptive analytics | | Partial Dependence Plot | Yes | Yes | Numerical & symbolic | Root Cause Analysis
Prescriptive analytics |
| Info |
|---|
| title | What can I do with each method? |
|---|
| Dynamic Model: User can manually simulate the change in an output variable when changing input variables (based on a predictive model or function variables) Partial Dependence Plots: Partial Dependence Plots (PDP) are a useful visualization tool to help interpret the results of predictive machine learning models, specifically how each input influences the output variable. This tool varies each input variable one-by-one keeping all other input variables equal to historical data and calculates the new predicted values. Sensitivity Analysis: Sensitivity Analysis is a useful visualization tool to help interpret the results of predictive machine learning models, specifically how variations in each input influence the predicted output. This tool varies each input variable and calculates the new predicted values. Then it computes the induced variation on the output. The result is represented as a box plot. For each input variable there is one box. Each box represents the output variation induced by the variation of one input alone. |
The right technique to the right problem !
| The question? | Analysis Type | Output | Type of algorithm
|
|---|
| Type | Sub-Type | Technique(s) | | What are the different operating modes in my production line? | Exploration | N/A | Unsupervised | Clustering | PCA K-Means Subclu IMS | What are the root causes of my quality issues? | Root Cause Analysis | Quality control (Bad or Good) | Supervised | Classification | Decision tree Extra/Adaboost Trees | When is my furnace drifting from normal operations? | Detect abnormal conditions | N/A | Unsupervised | Monitoring | ISHM Statistical Process Control | How can I check the influence of changes in my input variables on my yield? E.g. influence of reactor temperature on my yield. | Interpretation of Predictive modelling | Yield (% raw material in output) | Supervised | Regression | Sensitivity Analysis Partial Dependence Plots Dynamic Models | | Which sensors are correlated? | Correlation | N/A | Unsupervised | Hierarchical clustering (*) | Dendrogram | What is the range of manipulable parameters to optimize energy consumption? | Optimization | Energy efficiency (MWh/ton of produced product) | Supervised | Optimization | PRIM Optimizer | Which parameters influence the most the throughput of my line? | Root Cause Analysis | Ton/hour | Supervised | Regression | Regression Tree Extra/Adaboost Tree MART | | What changed on my production line between this month and last month? | Statistical Analysis | Month | Statistical Analysis | Classification | Statistical Tests
(Welch’s T-Test or Kruskal Wallis ANOVA) | | Has my energy efficiency changed over time? | Statistical Analysis | Energy Efficiency (MWh/ton produced) | Statistical Analysis | Regression | Box Plot Change Point Analysis Statistical Tests (Pearson or Spearman) | | Can I predict product quality before my lab results are ready? | Predictive modelling | % of composition | Supervised | Regression | Linear Regression
Regression Tree
Extra/Adaboost Trees
MART
Artificial Neural Networks
Partial Least Squares
K-Nearest Neighbours |
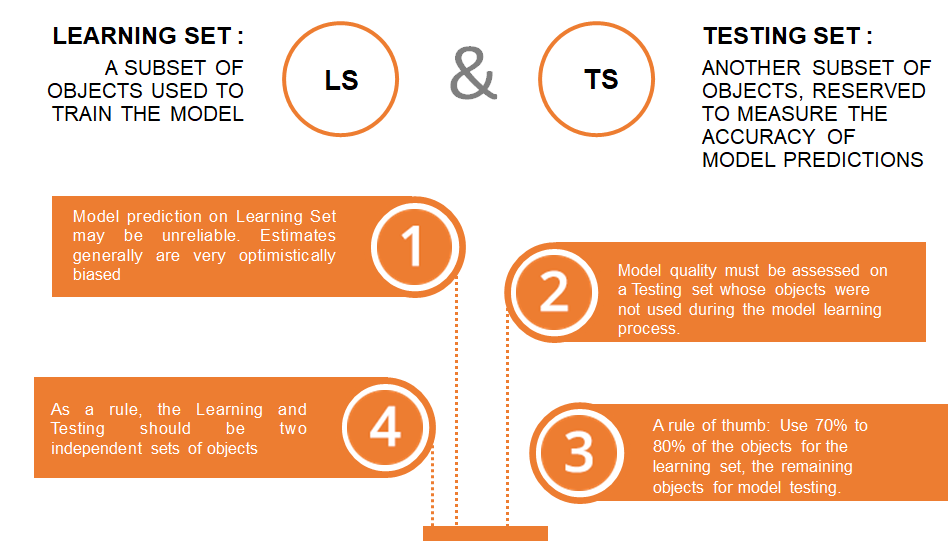
*Be careful to distinguish clustering offered by K-Means/Subclu (objective is to create clusters of similar records) from the hierarchical clustering offered by the dendrogram tool (objective is to group variables that are correlated together). In short, the first one clusters records, the second one clusters variables. Learning and Testing sets Learning and Testing sets are used for supervised machine learning techniques, when the purpose is to train a model. As a rule, the Learning and Testing should be two independent sets of records. - The Learning set is a subset of records used to the train the model.
- The Testing set is another subset of records used to measure the accuracy of the model predictions.
- Typically, the Learning set is 70-80% of the total amount of records, and the Testing set records is the remaining records that are "Not In" the learning set.
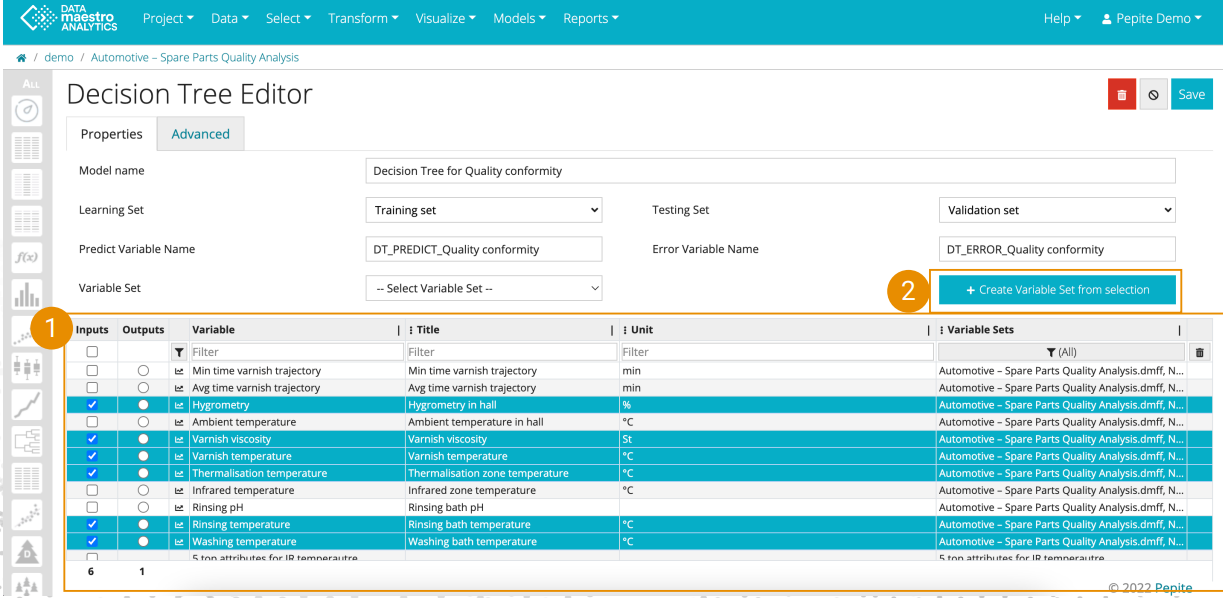
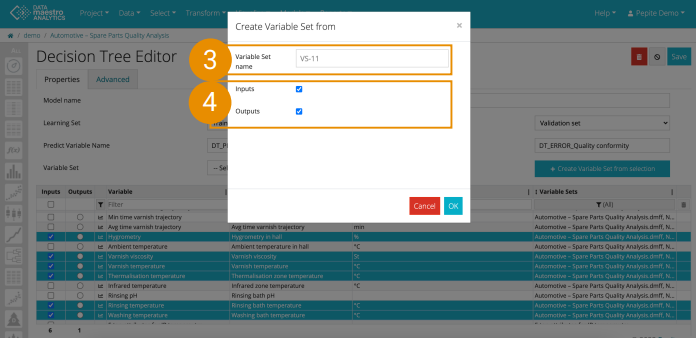
For more information, see Data. Create Variable set Once you have selected a list of variables, automatically create a Variable Set from the list of inputs and/outputs. - Select variables in the Variable picker
- Click “Create Variable Set from selection”
- Define a name for the Variable Set or leave by default
- Choose whether to keep input and/or output variables and click Ok.
Multi-Output
| Info |
|---|
| title | Multi-output for models |
|---|
| Train one supervised predictive model for multiple output variables based on the same inputs. Available for: Linear Regressions, Decision Trees, Extra Trees, k-Nearest Neighbors & Artificial Neural Networks |
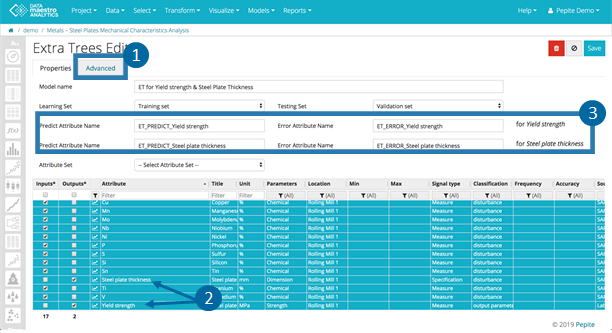
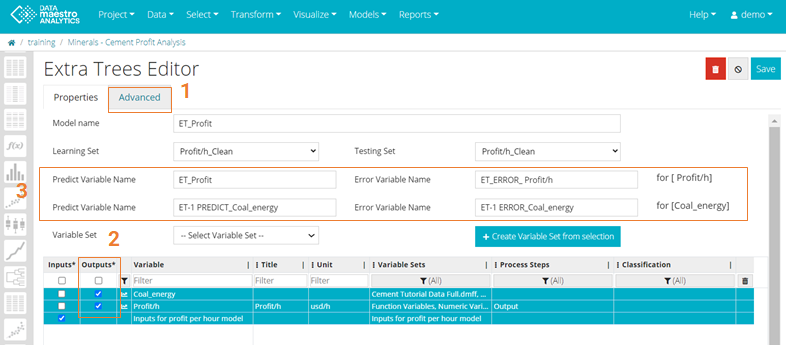
Find this option under Edit / Advanced / Enable Multi Output checkbox In Advanced tab, check Enable Multi Output checkbox. - Go to Properties tab and select additional outputs for the model.
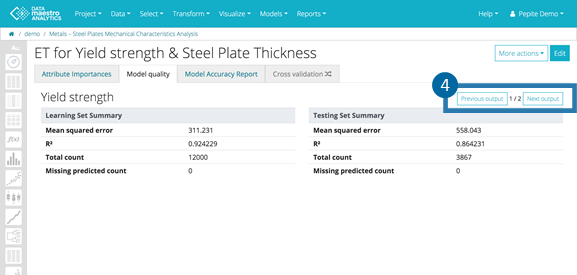
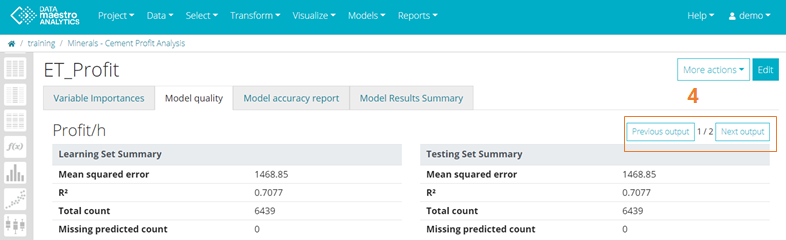
Define Predict and Error Variable Names, Optional. Review results for model quality and accuracy. The example below illustrates an Extra Trees model, there is only one Variable Importance tab but several Model quality tabs (one for each output model).
Cross Validation It is a model assessment and model selection tool. In Cross Validation, the Learning set is divided into several subsets and the model is trained on one of these subsets. Each sub-model of the Cross Validation uses the remaining partitions of the learning set as a testing set, to assess the sub-models' quality. Once the final model is created, the Testing set is used to assess the model quality and calculate the error. Several strategies for creating the partition of records are proposed: k-Fold, Stratified k-Fold, Leave-P-Label-out, Leave-P-out, Train-test split). Cross validation also helps identify the best model parameters. It is possible to enter values for the tunable parameters and the best values are presented as Cross validation results.
To launch this model tool, select in Models properties Cross validation strategy. Methods: Given a learning algorithm A and a set of parameters to evaluate, model selection is performed as follows : - for each combination of parameters :
- a new model is learned with the algorithm A initialized with the current set of parameters.
- its error is evaluated on the user-provided learning set using cross-validation.
- if the error is smaller than for all the previous models, the parameters and the model are retained as the best.
- At the end, the best model and parameters are returned and their generalization can be assessed on the test set specified by the user.
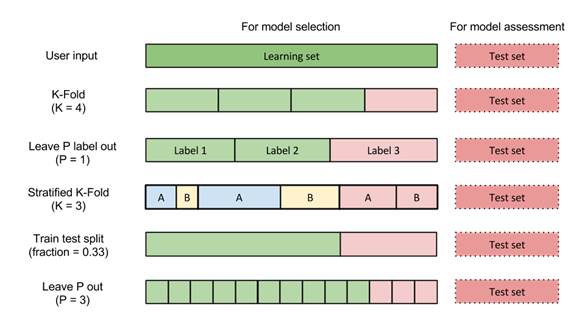
Cross-validation strategies implemented : - KFold : explained above (see scikit learn quote)
- Stratified KFold : the various folds are built such that their output distributions are similar
- Leave-P-Out : create every possible learning set/test set combination so that P records are extracted as a test set. For each combination, a model is learned on the the N – P records and the error is evaluated on the P remaining records. The final error is the combination’s errors average (in particular, for P=1, this strategy is equivalent to the Leave-One-Out one)
- Leave-P-Label-Out : a third-party variable associates a label to each record of the dataset and is used to create the folds. Then, performs like Leave-P-Out : create every learning set/test set combination so that P groups of labels are removed. For each combination, a model is learned on the K – P groups of labels (where K is the number of distinct labels in the learning set) and the error is evaluated on the P remaining groups. The final error is the combination's errors average (in particular, for P = 1, this strategy is equivalent to leave one label out) . This strategy make sense to avoid over-fitting when some groups of records are more correlated (period of the year, people,…)
- Train/test split : same principle as for model assessment. The learning set given by the user is splitted into yet another learning set and a validation set. The model is learned on the former and evaluated on the latter. This strategy is probably the less costly (in terms of computations) but performs poorly on small datasets as “results can depend on a particular random choice for the pair of (train, validation) sets” (scikit learn user guide).
Create Cross-validation strategy The parameters for this method are defined on tab Properties. On the Properties tab: Select a Cross-validation strategy from the list. Enter the parameters for the strategy selected. Enter the values for the tunable parameters, use comma to separate the values, indicated by this icon Click Train to generate the Model. Check Cross-Validation tab results.
Description of Cross-validation strategies: 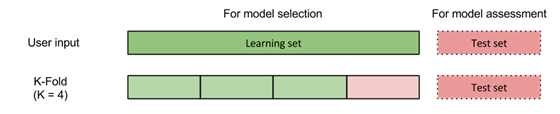
- Stratified K-Fold: Same as K-Fold except that folds are computed in order to provide to each output distribution close to the overall output distribution.
- K: Number of folders, default = 3, recommended K = 10.
- Output variable:Select the variable from the list.
- Seed:Initializes the random number generator used by the random part of the learning algorithm. Two identical seeds lead to two identical random number series, thus the same learning results.
 
- Label-P-Label-Out: Create folds based on third-party symbol variable, a given fold contains all records associated with a given label. This label can be period of the year or a record.
- P: Number of folds, default = 1.
- Label variable: Select the variable containing the label.

- Leave-P-out: The folds are created so that every combination of P records are removed. This method is useful for small data set but very expensive for large ones.
- P = Number of folds, default = 1.

Description: For Leave-P-out the time of resolution of an algorithm is dependent on the number of records in the training set. 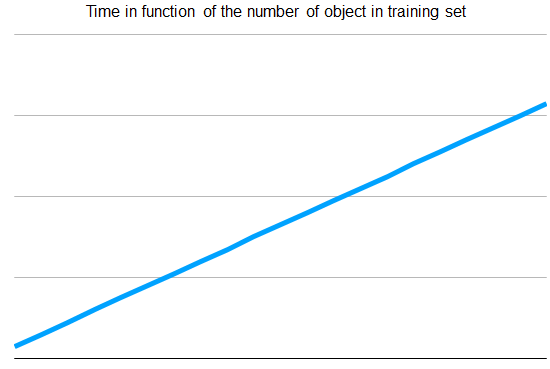
The number of records in the training set is inversely proportional to P. If the data set has 300 records and if P=50. Training set has 250 records. The result is as P increase, the time to train 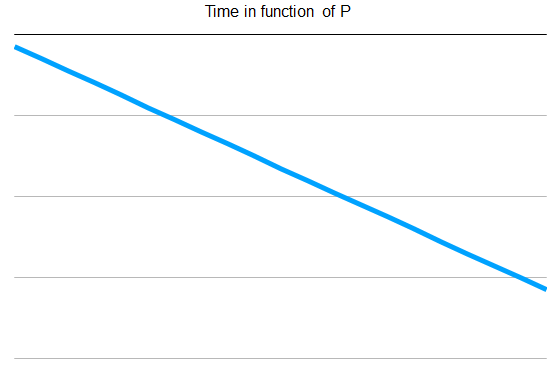 The number of algorithms to be tested is dependent of the number P with a binomial distribution.
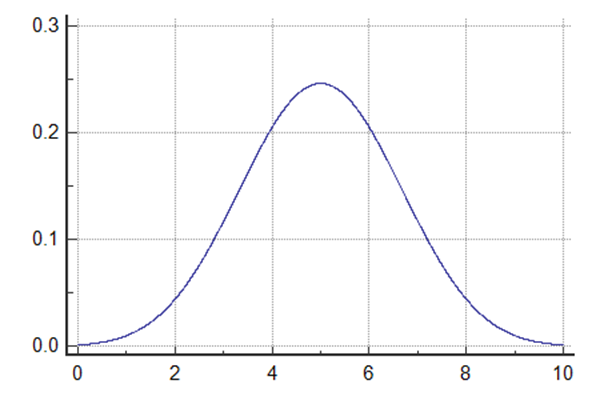
The addition of these two effects leads that a small value of P will lead to a slower Cross-validation. | Info |
|---|
| The quality of the cross validation model is linked with the number of records in the training set. A too large value of P will be faster but will lead to an unuseable model. |
- Train-Test split: It splits the learning set into training set and validation set. This method uses only one model to assess the error of a combination of parameters. It is the fastest method.
- Test fraction (%): Split fraction used by the Train/Test split strategy cross-validation. It defines the fraction of records that should be extracted from the learning set where the remaining records make up the validation set.
- Seed: Initializes the random number generator used by the random part of the learning algorithm. Two identical seeds lead to two identical random number series, thus the same learning results.

|