Term | Description |
|---|
Activation function (ANN) | Anchor |
|---|
| Activation-function |
|---|
| Activation-function |
|---|
|
| Transfer function that translates the input signals into output signals in a neural network. It connects the weights of a neuron to the inputs and determines the state or activation of the neuron. It is a function that switches the neuron “ON” and “OFF” depending on the input. Three activation functions are available: Sigmoid, Linear, Hyperbolic tangent. |
Adaboost | Boosting ensemble learning method used for regression and classification problems. at each iteration of the algorithm it builds a single tree by emphasizing the weights of the records that are misclassified or have a higher prediction error in the previous tree. It modifies the weights for the prediction of the next tree during training and, it uses the new weight vector to build the next tree. |
Alpha Values (Decision trees) | Anchor |
|---|
| Alpha Values (classification) |
|---|
| Alpha Values (classification) |
|---|
|
| Tests of statistical significance estimate how reliable the results are from a study based on a randomly selected sample. Indirectly it controls the size of the decision tree. Its main objective is to avoid splitting nodes if there is no statistical significance to split the node records as stated in the test node. A higher alpha value leads to a more detailed tree, while a lower alpha value results in a simplified model. Set by default to 0.01. |
Alpha (PRIM Optimization) | It is the proportion of data to be eliminated at each step in the construction of a PRIM model. For example, an alpha value of 0.1 will eliminate maximum 10% of data in each step. Set by default to 0.05 in DATAmaestro. |
Artificial Neural Network | Anchor |
|---|
| Artificial Neural Network |
|---|
| Artificial Neural Network |
|---|
|
| Machine learning algorithm used for classification and regression. It is a set of connected input/output units in which each connection has a weight associated to it. During learning, the network learns by adjusting the weights. The inputs pass through an input layer, are weighted and fed simultaneously to the second layer (hidden layer). The outputs of one hidden layer can be inputs of another hidden layer and so on. |
Average (Statistical information) | Arithmetic mean for a given variable across a given dataset. |
Average (Filling missing value) | Technique used to fill missing values. This method will create a new variable and replace missing values in the data set with the arithmetic mean of the original variable. |
Beta (PRIM) | It sets the stopping criteria for the PRIM algorithm. It is equivalent to the minimum proportion of data remaining in the final box (optimized zone). |
Box Number (PRIM) | It defines the number of boxes to be built for PRIM analysis. |
Box (PRIM) | It is an optimized zone identified within the historical data for a given output variable based on constrained ranges of all input variables. It is possible to construct multiple boxes (optimized zones). |
Box plot | Anchor |
|---|
| Alpha Values (classification) |
|---|
| Alpha Values (classification) |
|---|
|
| Method for illustrating the distribution of data by means of quartiles. Quartiles of data are three points that divide the records of a variable into four equal groups, each composed of a quarter of data. In the results table, the minimum, maximum and quartiles are calculated for each Class (ranges of the variable defined in X). The first quartile (Q1) is the middle value between the smallest and the median values. The second quartile (Q2) is the median value. The third quartile (Q3) is the middle value between the median and the highest values. |
Calculate cluster silhouette | The cluster silhouette is an indicator of the clusters' consistency. The result will be between -1 and 1. The closer the silhouette is to 1, the better each record fits within its cluster. |
Candidate variable count (Extra Trees) | At each test node, the best split is determined among K random splits and each one is established by a random selection of input variables and a threshold. The candidate variable count is the number of input variables which are going to be chosen randomly for the test node. If this parameter is not defined by the user, the algorithm is going to choose it automatically, depending on the type of the model. For regression, it considers all variables and; for classification, the square root of the number of variables. Alternatively, the user may choose to manually define this parameter or trial several values during Cross Validation. |
Classification | Category of supervised learning where the output or goal is to predict a discrete or symbolic variable, for example, predict energy consumption as High-Medium-Low. |
Clustering | Anchor |
|---|
| Alpha Values (classification) |
|---|
| Alpha Values (classification) |
|---|
|
| Method of unsupervised learning used to define groups or patterns within the data. Records of the same group (cluster) are more related to each other than those of other clusters. |
Cluster number (k-Means) | It defines the number of clusters to be created by the K-Means clustering algorithm in which each observation belongs to the cluster with the nearest mean. |
Coefficient (Statistical Process Control) | It is used to calculate the control limits as a function of the sample distribution. |
Common LISP | Anchor |
|---|
| Alpha Values (classification) |
|---|
| Alpha Values (classification) |
|---|
|
| It is one of the major dialects of the LISP programming language. It allows a combination of object-oriented, procedural and functional programming. |
Condition (Cond.) | It is a numerical or symbolic variable used to show interaction effects with another variable (values are represented by different colors on Histograms, Scatter plots and Standard Reports). |
Conditional class count | Anchor |
|---|
| Alpha Values (classification) |
|---|
| Alpha Values (classification) |
|---|
|
| The number of buckets for the condition or number of discretized groups for a conditional variable added as color coding to Histograms and Scatter Plots. |
Constraint Functions/Models (Optimizer) | Constraint Functions/Models are designed to ensure that the Optimizer respects all constraints on the process when varying the values of Manipulable inputs. All function variables and predictive model outputs can be selected as Constraint Functions/Models. |
Control Charts | Control charts are used to monitor quality. There are two chart types: univariate and multivariate. Univariate charts are used to graphically display a single process characteristic, and multivariate charts to represent multiple characteristics. For more information about using control limits in DATAmaestro, see Process control. |
Cross Validation | Anchor |
|---|
| Alpha Values (classification) |
|---|
| Alpha Values (classification) |
|---|
|
| It is a model assessment and model selection tool. Cross validation allows learning of a model on some partition of the learning set and testing by evaluating the error on another, independent, set of records (not belonging to the learning set). Several strategies for creating the partition of records are proposed: k-Fold, Stratified k-Fold, Leave-P-Label-out, Leave-P-out, Train-test split). Cross validation also helps identify the best model parameters. It is possible to enter values for the tunable parameters and the best values are presented as Cross validation results. For more information, refer to Cross Validation. |
Cumulative plot (Histogram) | It is a plot type option presented in the Histogram editor. It is a curve that shows the cumulative frequency distribution. |
CUSUM | Anchor |
|---|
| Alpha Values (classification) |
|---|
| Alpha Values (classification) |
|---|
|
| Control chart that displays the cumulative sums of the deviations of each record value from the target value. Typically used to detect small drifts in process mean. |
Decision tree | Decision support supervised learning method for regression and classification models. It uses tree-like models of decisions structured as “if then” rules and seeks to reduce “entropy” or variability in each leaf/node. |
Default value ( Fill Missing values) | Technique used to fill missing values. This method will create a new variable and replace missing values in the data set defined as a default value. |
Dendrogram | Anchor |
|---|
| Alpha Values (classification) |
|---|
| Alpha Values (classification) |
|---|
|
| Tree diagram used to illustrate the distribution of clusters and the linear correlation between variables. The clusters are created by Hierarchical Clustering, a method of clustering which seeks to build a hierarchy of clusters. The algorithm presented in DmA is an Agglomerative type, each observation starts in one cluster and pairs of clusters are merged as it moves up the hierarchy. |
Differentiated variable | It generates the derivative of a variable. Three methods are available: Newton, Symmetric and High order. |
Direction (Optimizer) | It defines if a model or a function variable should be maximized or minimized. |
Discretized variable | It creates a symbolic function variable based on a numerical variable, by dividing continuous data into discrete categories using a set of “less-than” thresholds. For a given value, the method will associate the symbol of the first threshold. If none of the thresholds match, the value is associated to the default symbol. |
Discretized time variable | It creates a symbolic function variable extracting relevant and understandable information such as year, months, day of the week, etc. out of a numerical time |
DMFF (DATAmaestro File Format) | Private file format used for storing table data in DATAmaestro, with the advantage of a quick response time for large datasets. |
Epsilon (Subclu and ISHM) | Anchor |
|---|
| Alpha Values (classification) |
|---|
| Alpha Values (classification) |
|---|
|
| The epsilon is the maximum distance between two records. If the distance between an evaluated record and another record is lower than epsilon, the latest is added as the neighbor of the evaluated record. A high value of epsilon implies a low number of clusters and therefore, lower precision. The value of choice depends on the dataset and, it is a compromise between the minimum number of points and the distance between the points in a cluster. |
Epsilon (IMS and ISHM-IMS) | It is the maximal distance for a point to be in a cluster. A larger value tends to lead to a lower number of clusters. |
Ensemble trees methods | Supervised approaches that use the combination of models to improve a model accuracy. Each technique combines a series of learned models (classifiers or predictors) with the aim of creating an improved aggregated model. The main advantage of ET methods is that, compared to a single tree, it has the ability of reducing considerably the variance and/or bias. There are different techniques of ensemble methods. DmA proposes two approaches: boosting (Adaboost and MART) and randomized-based (Extremely Randomized Forests). |
Error Variable Name | All predictive models (Regression and Classification) provide two output variables: Predict Variable and Error Variable. The Error Variable provides the difference between the predicted output values and the real output values. By default, if no name is entered, the default name is generated based on model type and the output variable. For example, a decision tree by default is DT_ERROR_[OUTPUT]. |
Extra trees (Extremely Randomized Forests) | Supervised learning method for classification or regression models. It randomly creates an ensemble of decision trees and aggregates the results to provide the importance of the input variables on the output. At each test node, the optimal split is obtained by searching among K random splits, each split chooses one variable randomly (without replacement) and determines a random test from it. |
Excel time | Excel date and time stored as a number, known as date serial number. The integer portion represents the date and the decimal portion is the time. For more information, please check Excel Date. |
Fill curve | Visualization functionality that fills or colors the area below a trend. |
Fill missing value | It creates a variable or set of variables replacing the missing values with a value designated by the strategy adopted such as default value, average, the previous or the next values or an interpolation of the previous and next records. |
Filter (Record set) | Method for creating record sets (data filters) based on filtering a particular variable (numerical or symbolic) based on the given filter rules (less than, greater than, etc.). |
Filter Missing | Method for creating record sets that removes any records (or rows) missing from any variables in a given variable set. NB: Data sets with high proportions of missing data may result in empty record sets. |
First (Record set) | Record set rule that indicates records selected from the front of the current Record set. For example, “First 100” will select the first 100 records (or rows) within the selected data set (or record set if combining record set rules). |
Function Variable (formerly Function Attribute) | Used to create new variables by applying mathematical operations on variables. The expression can be created using different programming languages such as JavaScript, Python, R and common LISP. |
Gap analysis | Technique used to identify gaps between a current state and a targeted one. |
Generalization level | Visualization tool that defines the degree of resolution for a collection of points. Lower values provide lower resolution (large squares or fewer pixels) and higher values provide greater resolution. |
Gradient descent (ANN) | Learning function or optimization method used for training Artificial Neural Networks (ANN). The learning function searches a vector of weights in which the error function takes a minimum value. Gradient descendant is the simplest learning algorithm and a first order method. It optimizes the performance of the network by adjusting the weights, it goes in the direction of the greatest error decrease in the variable space trying to find minimum error. It provides many local minimal or flat regions. There are no guarantees for convergence. |
Handle missing value | This property is only available for tree based methods (Decision Trees, Ensemble Trees, MART, Adaboost) as most machine learning methods cannot provide an embedded support for missing values. If this option is deactivated, the procedure will remove any rows which contain at least one missing value. This may cause a significant loss of information. Handle missing values therefore allows tree models to be calculated without significant information loss. |
High order (Differentiated variable) | Method used for derivative calculations. For every variable, the derivative is calculated using a higher-order (order higher than 2) difference quotient formula: [-f(t+2*Step)+8f(t+Step)-8f(t-Step) + f(t-2*Step)]/12*Step. Step is a parameter that defines the step length of the differential function. |
Histogram | Graphical representation of a numerical data distribution. For a numerical variable, the data is divided into consecutive and non-overlapping adjacent intervals, often of equal sizes. The height of each bar is proportional to the frequency – number of cases per interval. For symbolic variables, the intervals represent the classes (categories) of that variable. There are three histogram options in DATAmaestro, choose from the following plot types in the properties: Histogram, Pareto and Cumulative plot. |
Hyperbolic tangent (ANN) | Activation function for Artificial Neural Network (ANN) models with the typical “S-curve” or Sigmoid curve. It is very similar to the Sigmoid function. It can be considered as a rescaled version of a sigmoid function, since they have the same characteristics but its output between the range [-1,1]. Tanh is also a widely used activation function. |
Infix | Infix - characterized by placement of a binary operator between the operands <a + b is expressed in infix notation>. |
Intersect (Record set) | Record set rule that allows the combination of an existing record set with additional rules (or with additional record sets). When combining two (or more) record sets using intersect, this is equivalent to keeping data points that are in both record set 1 “and” record set 2. |
Interpolation (Fill missing value) | Technique used for filling missing values which creates a new variable using the linear interpolation between the previous and next value for each missing data point. |
ISHM | As its name suggests is an asset monitoring algorithm based on Clustering (K-means or Subclu in DATAmaestro). For a given input vector, each cluster defines a range of allowable values for each parameter. Points that are inside the inner center of the cluster are within the system operating range, those further away can be considered as outliers or process drifts. |
ISO-8859-1 | Character encoding type. It is a single byte fixed length basically used for Western Europe alphabets. Could be specified by the user when a CSV is uploaded in DmA. |
K (Cross Validation) | Number of folds used for K-Fold and Stratified K-Fold cross-validation strategies. |
K (K-nearest neighbors) | Number of neighbors (data points) to be used by for K-Nearest-Neighbors model queries. The best choice of k depends on data. A large value of k (>10) reduces the effect of noise on classification but, the boundaries between classes are less distinct. Performance increases. A small value of k will be able to capture fine structures, if it exists in the feature space. However, if k is too small it may lead to overfitting.
In binary classification problems, it is better to choose k as an odd number in order to avoid tied votes. |
K (K-means) | Number of clusters for K-means clustering algorithm, refer Cluster Number. |
K-fold (Cross-validation) | Strategy used in cross-validation. The learning data set of size N is divided in K number of consecutive folds containing N/K records. A model is trained using K-1 of the folds as training data; the resulting model is validated on the remaining part of the data (i.e., it is used as a test set to compute a performance measure such as accuracy. The error is computed by making the average of the error of each K models on their respective leaf-out fold (test set). |
K-means | Type of unsupervised learning clustering algorithm used to define groups or patterns within the data based on the distance between points. |
K-NN | It is among the simplest machine learning algorithms. The method can be used for classification and regression. In classification, the record is assigned to the majority class of its k nearest neighbors. K is the number of neighbors and it is a positive integer number. If k=1 the record is assigned to the class of a single nearest neighbor. In regression the predicted value is the average value of the k nearest neighbors. For high-dimensional data, k-Nearest neighbor can have a very poor performance. Therefore, before applying the k-NN algorithm, it is recommended to conduct dimension reduction using other models such as PCA, Dendrogram or Extra trees or Decision trees. |
Label variable (Cross-validation) | Symbolic variable containing the label to be used in Label-P-Label-out cross-validation strategy. |
Last (Record set) | Record set rule that indicates records selected from the end of the current record set. For example, “last 100” will select the last 100 records (or rows) within the selected data set (or record set if combining record set rules). |
Latent variable count | Number of latent variables which are inferred from the observed ones through the Partial Least Squares model. Latent variables reduce the dimension of data since observations can be aggregated to represent more basic conceptions. |
LCL variable name (Statistical process control) | Parameter of the Statistical Process Control method which defines the lower control limit (LCL) above this value the process is considered to be under normal control. Graphically, the LCL is represented by a horizontal line below the average. |
Learning function (ANN) | Parameter that defines the optimization algorithm that updates weights and bias values to minimize the error function. Two learning functions are available within DATAmaestro: Levenberg-Marquardt and Gradient descent. |
Learning rate (MART) | Adjusts the speed convergence for the MART method. A higher/lower learning rate shrinks the contribution of each tree. This parameter, comprised between 0 and 1, slows down the output correction at each iteration of the MART algorithm. A small value of this parameter is indicated to avoid over-fitting. Its default value is set to 0.1. |
Leave-P-out (Cross validation) | Strategy used for cross validation, folds are created so that every combination of P records are removed. For each combination, a model is learned on the N – P records and the error is evaluated on the P remaining records. The final error is the average error. This method is useful for small datasets but is very expensive for large ones. |
Leave-P-label-out (Cross validation) | Strategy used for cross-validation. It creates folds based on a symbolic variable other than the output variable, examples, symbolic time such as months of the year, product identifier, etc. A given fold contains all records associated with a given label. There is a possibility of choosing the number of folds (parameter P) used for the model evaluation. The model is learned with the remaining data, excluding the removed folders. |
Levenberg-Marquardt (ANN) | Learning function or optimization algorithm used for training Artificial Neural Networks (ANN). It is a popular method used as a linear least-squares solver. Recommended as a first choice (instead of Gradient descent) since it is an iterative technique that reduces the performance function in each iteration. It is the fastest training algorithm for small- and medium-size networks. |
Linear (ANN) | Type ofactivation function for Artificial Neural Network (ANN) models which is a linear operator. The network would apply a linear combination to relate input to outputs at each neuron. The network can learn effectively using a linear activation function if the weights are initialized with less randomized values. To learn more complex networks, it is fundamental to add non-linear activation functions. |
Linear regression | It is the simplest form of regression. The data is modeled as a linear combination of input variables to create an output predictive model. The model searches a line (y=ax+b) that fits best the data. The task is to find coefficients (weights) to provide the best fit to the training data. The value of the coefficient quantifies the strength of the relation between the output and the different inputs. |
Loss function (Adaboost) | Function used to update after each boosting iteration the weights - only in Adaboost Regression. The loss function is the prediction error for the record divided by the maximum error among all records. The functions provided are: linear, squared and exponential. For classification, the loss function field is ignored. |
Lower shift (Shifted variables) | Parameter used for (e.g. time) shifted variables, specifies the lower bound of the window. A lower shift of -1 would create an additional variable in the data set that has the current value equals to the value of the preceding row. |
Manipulable variables (Optimizer) | Manipulable variables are Target Function/Model inputs that can be purposefully changed on the process. If a Function/Model input is not defined as Manipulable, it is considered as a disturbance variable by the optimizer. The optimizer will then seek to vary the values for each manipulable to optimize the Target Function/Model value. |
MART | Instance of gradient boosting applied to regression problems. It builds a powerful model out of weak models. It is only implemented as a regression model. Each tree of the ensemble is built with the Single Tree building algorithm using as output of the learning records the residual error, i.e. the difference between the true output and the prediction of the current ensemble |
Max iteration count (Optimizer) | Max iteration count limits the optimization iterations to a maximum number if no convergence is detected for the Optimizer. |
Maximum number of cycles (ANN) | It limits the learning iterations (or Epochs) to a maximum number if no convergence is detected for Artificial Neural Network (ANN) models. |
Maximum number of iterations (k-Means & ISHM) | k-Means parameter that fixes the number of iterations for cluster calculations. A high value provides a better quality clustering but there is a risk that the calculation will take longer. |
Maximum number of splits (Tree based methods) | It sets the maximum number of decisions or splits for a decision tree (or other tree based methods). The tree grows based on the stop splitting criteria until it achieves the maximum number of splits. Once the value is achieved the decision tree stops growing. Important remark for Decision Trees: although its value represents no hard limit for expansion, the alpha value may limit the tree increase before achieving maximum number of splits. |
Max record count (Optimizer) | Max record count (n) limits the number of records optimized. Based on the selected Record Set, the first n number of records will be optimized. |
Maximum split count (Adaboost, Extra trees and MART) | it is a parameter used to control the depth of the trees. For Extra trees, by default, the trees are fully developed, the case is empty. However, when using this parameter, the complexity and the computation time of the trees are reduced. For boosting methods (Adaboost and MART), by default, the maximum number of splits is defined as 10, so, each tree has 10 node splits. The accuracy of the model can be improved if this value is bigger than 10. |
Method (Optimizer) | In the context of the Optimizer, the method defines the optimization algorithm applied. There are two methods implemented in DATAmaestro: Swarm Optimization and Nearest Neighbors. |
Method (PRIM) | In the context of the PRIM optimization analysis. “Max” stands for maximizes the target variable (average value or number of occurrences) and “min” stands for minimizes the target variable (average value or number of occurrences). |
Minimum number of points per cluster (ISHM - Subclu) | The minimum number of points at a distance lower or equals than epsilon needed to create a cluster. |
Minimum points | In Subclu, the minimum number of points at a distance lower or equals than epsilon needed to create a cluster. |
Min cluster Dimensions | As SubClu start by creating cluster of lower dimensions (start by 1), it will keep the cluster with at least "Min Dimensions" number of dimensions. A Dimension is created by a variable (3 inputs variable equals 3 maximum dimensions). |
Model count (Ensemble trees models) | It indicates the number of M decision trees to be built for Ensemble trees models, usually more models is better for the model quality however this increases the execution time. |
Model type (ISHM) | Choose the clustering method, K-means or Subclu, to be used for the ISHM model. |
Moving average | Method used to smooth noisy data by taking a average of several data points, compared to the current data point, across a period of time. |
Newton (Differentiated variable) | Method for derivative calculations. For every variable, the derivative is calculated using a First-order difference quotient formula: [f(t+Step)-f(t)]/Step. Step is a parameter that defines the step length of the differential function. |
Next (Fill missing value) | Technique used to fill missing values, this method will create a new variable and replace missing values in the data set with the next value compared to the given missing value. |
Not-in (Record set) | Record set rule that excludes all data contained within a specified record set. |
Normalize (Linear Regression and Clustering) | Scaling option that transforms the variable values to range from 0 to 1. The value is calculated as follows: scaled(x) = (x - min)/(max - min) where the min and max values are based on the learning data set. |
Normalized (CUSUM) | CUSUM parameter can be used to normalize the average or standard deviation. The average normalization performs a shift of every values by the average. The final value of the CUSUM will be zero. The STDEV performs a rescaling of data as a result the STDEV becomes 1. It is possible to use both approaches simultaneously the result will be data with an average = 0 and a stdev =1. |
Number of causes (ISHM) | Indicates the number of variables which could explain the ISHM-distance value for each record or data point. If number of causes is zero then no causes are displayed. |
Number of clusters (k-Means) | K number of clusters or number of groups within the data in which each observation belongs to the cluster with the nearest mean. |
Number of hidden layers (ANN) | Number of layers between the input and output layer of a neural network model (at least 1 in DATAmaestro). There is no rule to define the right number of hidden layers, in most industrial cases 1 layer is sufficient, more layers can model complex behaviors but tend to overfit. |
Number of nearest points (ISHM-Subclu) | Indicate the number of nearest point in the nearest cluster used to compute the ISHM Distance. |
Number of neurons per hidden layer (ANN) | Number of units per hidden layer where each unit is weighted by a numerical parameter. |
Numerical | Value is an integer or real number that can be numerically ordered. |
Optimize cluster number | With the help of the cluster silhouette score, will optimize the number of clusters needed. The optimization will search for a cluster number between 1 and the "Cluster Number" value. It is necessary to calculate the Cluster Silhouette for this to work. |
Outlier | An outlier is a piece of data that is numerically distant from the rest. Whether it is caused by error or abnormality, outliers are normally removed from analysis for clarity. According to the three sigma rule (empirical rule), nearly all values stand within three standard deviations of the mean. |
Overfitting | Overfitting occurs when a statistical model describes random error or noise instead of the underlying relationship. Overfitting generally occurs when a model is excessively complex, such as having too many parameters relative to the number of observations. A model which has been overfit will generally have poor predictive performance, as it can exaggerate minor fluctuations in the data. |
P (Cross-validation) | Number of folds used in Label-P-Label-Out and Leave-P-Out cross-validation strategies. |
Pareto (Histogram) | Bar graph for symbolic variables only, where the symbols are represented in descending order. The lengths of the bars represent the frequency of occurrence of the set of categories of a symbolic variable. The purpose of this chart is to highlight the most important among a large set of categories. |
Pareto (Models and Analysis) | Chart representation of the results for certain models such as Extra trees, Adaboost trees, MART and Statistical tests. The diagram organises the information in descending order of importance of the causes (the most important cause first). The length of the bar represents the variable's impact on the output, in percentage. The Pareto provides the information of the top variables influencing a given output. |
PCA | It is defined as an orthogonal linear transformation of data. It converts possible correlated variables into a new coordinate system of linearly uncorrelated variables called principal components or principal variation modes. The first principal component has the largest possible variance (or correlation matrix that measures of joint variability of variables) and each following component must have the highest possible variance, however, the constraint is that the component must be orthogonal to the preceding ones. The resulting vector is an uncorrelated orthogonal set. This approach can help to reduce the number of explanatory variables strongly related to each other into a few components. |
PLS | Creates a linear regression method in a transformed projection of the space problem. It combines features from principal components analysis (PCA) and multiple linear regression. The model aims to explain the observed variables in terms of latent variables (inferred from observed variables). As latent variables reduce the dimension of data it can be very useful for regression problems with a large number of input variables. |
Predict Variable Name | All predictive models (Regression and Classification) provide two output variables: Predict Variable and Error Variable. The Predict Variable provides the predicted output values. By default, if no name is entered, the default name is generated based on model type and the output variable. For example, a decision tree by default is DT_PREDICT_[OUTPUT]. |
Previous (Fill missing value) | Technique used to fill missing values, this method will create a new variable and replace missing values in the data set with the previous value compared to the given missing value. |
PRIM Analysis | Anchor |
|---|
| PRIM analysis |
|---|
| PRIM analysis |
|---|
|
| Patient Rule Induction Method (PRIM) is a data mining technique used to find subregions in the input space with relatively high (low) values for the target variable. By construction, PRIM directly targets these regions rather than indirectly through the estimation of a regression function. The method is such that these subregions can be described by simple rules, as the subregions are (unions of) rectangles in the input space. |
Pruning set (Trees) | It evaluates the pruned tree. A pruned tree uses a pruning technique that, reduces the size of the learning tree by removing nodes that is not able to provide additional information. The aim is to optimize the size of the tree without reducing the accuracy. The dataset is divided in 3 independent sets: learning, test and pruning sets. |
Quartiles | In descriptive statistics, the quartiles of a ranked set of data values are the three points that divide the data set into four equal groups, each group comprising a quarter of the data. One definition of the lower quartile is the middle number between the smallest number and the median of the data set. The second quartile is the middle observation, also called the median of the data. The third quartile can be measured as the middle value between the median and highest values of the data set. |
R | Popular programming language mainly used for statistical and data science. Function variables can support expressions written in R. |
Random (Record set) | Record set rule that selects records randomly (ensures a uniform distribution). For example, “random 100” will randomly select 100 records (or rows) within the selected data set (or record set if combining record set rules). |
Record (formerly Object) | A record is simply an indexed value that identifies a specific instance, data point, in a database. The identifiers are established based on the row index of the table. |
Record set (formerly Object Set) | A record set is a set of data points, specific instances, records or rows in a database. Record sets can be created based on a series of rules (First, Last, Random, Intersect, Filter, etc) or via rulers on all visualization graphs. |
Regression | Category of supervised learning where the output or goal is to predict a continuous or numerical variable, for example, predict energy consumption which has a range between 0 and 25. |
Relative frequencies (Histogram) | Type of histogram where the observation frequencies could be presented as a percentage. |
Restrict symbol peeling (PRIM) | If this parameter is selected the algorithm does not remove more records than the alpha value at each step. In case there are not enough symbolic values, this criterion is not considered. If deactivated, for symbolic variables, it allows the algorithm to peel more than alpha values at each step. Note: for numerical variables with a limited amount of values, a similar problem occurs. |
Scale factor (Summary chart) | Multiplication factor by which all y-axis variables will be adjusted. |
Scatter plot | Cartesian coordinate graph type (X-Y plot). It displays two variables, however a third one can be displayed if a condition (cond.) is designated. The purpose of this graphic is to identify possible relations (correlations), if any, between two or three variables. |
Script filter (Record Set) | Method for creating record sets based on scripting rules. Rules can be scripted in Javascript, Python or R. |
Search cluster number (k-Means) | Uses the Silhouette indicator to select the best number of clusters among a minimum (equal to 1) and a maximum number of clusters (parameter Number of clusters in ISHM). It iterates from 1 to Number of clusters and checks if there is an improvement of the Silhouette indicator. Therefore, for having an actual improvement it is better to put a number of cluster bigger than 5. |
Seed | Initializes the random number generator used by the random part of the learning algorithm. Two identical seeds lead to two identical random number series, thus the same learning results. |
Sigmoid (ANN) | Activation function for ANN models with the typical “S-curve” or Sigmoid curve. It is like the step function but it has a smoother derivative. The output of the function is always in the range[0,1]. It is the closest to the input-output relation of biological neurons. Therefore, it is often used in ANN to introduce nonlinearity in the model. The sigmoid derivative is easy to calculate which helps the weight calculations. It is one of the most used activation functions. |
Silhouette | Method used to validate the consistency within clusters of data for K-means and Subclu clustering. It brings a concise representation on how well each record fits within its cluster. |
Shuffle (Cross-validation) | This is a variation of the k-Fold method that can randomly shuffle data before splitting them into k folds. The parameter Seed initializes the random shuffling each time the k-Fold is iterated. Two identical seeds lead to two identical shuffling. |
Skip regularization (ANN) | Once selected, usually inhibits the ANN from performing regularization, a regulator designed to control the network complexity and thus preventing over-fitting, e.g. penalty for complexity. |
Skip scaling (ANN) | Once selected, it prevents input variables of the ANN models from being rescaled and therefore, making them numerically comparable. |
Snap | The Snap method samples by taking the last stored value within each time interval. In case there are no stored values within a given interval the snap method considers the last value stored. An instantaneous value at each time interval will be extracted, no aggregation is provided. |
Standard report | DmA feature which enables the creation of a report containing a trend, a histogram and scatter plots. The variable defined in Var. is the main variable and is compared to those defined in Comp. The time variable is defined in Time/Temp. If required, a conditional variable for the histogram and scatter plots, can be defined in Cond. |
Standardize ( Linear Regression and Clustering) | Scaling option that transforms the variable to have a mean of 0 and a standard deviation of 1. The value is calculated as follows: scaled(x) = (x - µ)/(STDEV)
where the average (µ) and standard deviation (STDEV) values are calculated on the learning data set. See also Normalize. |
SPC | Method for defining process control limits. It can verify the assumption that the process is stable. The results provided as upper and lower limits indicate the range in which the process is under control. The measured values should be within those limits, otherwise the process is out of control and should be examined. |
Stratified-K-fold (cross-validation) | Preferably used for classification problems which the results can be easily biased by under and over representation of classes in the output variable. It is a variation of K-fold but the difference is that it preserves the class distribution within each fold. The folds are selected so that each fold contains approximately the same proportion of target class labels. For regression problems, the mean output value is approximately equal in all folds. |
Subseq (Record set) | Record set rules that span from row n to to row m within the selected data set (or record set if combining record set rules). |
Subclu | Unsupervised clustering algorithm used to define groups or patterns with the data based on the density of data points. It marks as outlier’s points that lie alone in low-density regions. Each cluster is expanded one dimension at a time into a dimension that is known to have a cluster that only differs from previous clusters in one dimension. Therefore, it is not necessary to define the number of clusters as in k-Means. |
Summary chart | Visual tool that uses bars to summarize data among categories. The bar chart consists of two axis X and Y. The X axis is the time variable (discretized based on the period type) and the Y axis variable can be one or several numerical variables. The period type can be changed: year, month, week, day, hour, minute and second. The variable summary type (based on sum, average, min or max) and a scale factor (multiplication factor) can also be selected. |
Summary type (Summary chart) | Method used to display data in the summary chart. The options available are: average, minimum, maximum and sum. |
Supervised learning | Machine learning task that uses an algorithm to learn a mapping function to predict an output from input variables. The goal is to approximate the mapping function well enough, so that, when there is new input data the output variable can be adequately predicted. The output can be symbolic or numerical. |
Symbolic | Value is a string or symbol, cannot be ordered unless if it implies an intuitive order (e.g. high low). |
Symmetric (Differentiated variable) | Method used for derivative calculations. For every variable, the derivative is calculated using a Second-order difference quotient formula: [f(t+Step)-f(t-Step)]/2*Step ; Step is a parameter that defines the step length of the differential function. |
Swarm (Optimiser) | "Differential Evolution (DE): The multi-agent optimization method known as Differential Evolution (DE) is originally due to Storn and Price (Differential evolution - a simple and efficient heuristic for global optimization over continuous space. Storn, R. and Price, K. s.l. : Journal of Global Optimization, 1997, Vol. 11, pp. 341-359.). Many DE variants exist and a simple one is implemented in the DE-class and a number of different DE variants are available through the DESuite class. DE uses a population of agents. Let denote the position of an agent being updated and which has been picked at random from the entire population. Let be its new potential position computed as follows (this is the so-called DE/rand/1/bin variant): 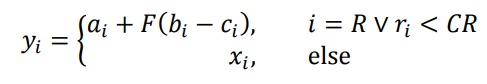
where the vectors , and are the positions of distinct and randomly picked agents from the population. The index is randomly picked and is also picked randomly for each dimension . A move is made to the new position if it improves on the fitness of . The user-defined parameters consist of the differential weight , the crossover probability , and the population-size." This extract was taken from the document SwarmOps for Java. |
Step (Shifted variables) | Specifies the (time) step for (time) shifted variables. A step equivalent to the step window will result in only one new variable being calculated, whereas a step less than the step window will result in N new variables being created. |
Step duration (Differentiated variables) | Step length of the differential function. Denominator parameter of the derivative equations: order 1, order 2 or higher order. |
Target | In the context of the PRIM optimization, Optimizer and Dynamic Inputs analysis, “Target” defines the optimization objective. “Maximization” seeks to maximize the function value and “Minimization” seeks to minimize the function value. For PRIM, “Maximization” seeks to increase the average value or number of occurrences of the target class, whereas “Minimization” seeks to decrease the average value or number of occurrences of the target class (refer Target Symbol). |
Target Function/ Model (Optimizer) | In the context of the Optimizer, the “Target Function” can be any Function Variable or Model. This function will be used to predict the output value during optimization. |
Target Min (Optimizer) | Minimum value that target model computation may lead to. It doesn't limit the output of the optimizer but it is necessary for the optimizer computation. It should be a realistic minimum value. |
Targer Max (Optimizer) | Maximum value that target model computation may lead to. It doesn't limit the output of the optimizer but it is necessary for the optimizer computation. It should be a realistic maximum value. |
Target Symbol (PRIM) | Symbolic variable used as the objective for a PRIM optimization model. The PRIM model will seek to minimize or maximize the probability of the target symbol in the final box(es). NB: This field is case sensitive, e.g. stable or STABLE are considered different values. For numerical optimization problems this field should be left empty. |
Target value (Gap analysis) | Gap analysis function. For a maximization gap analysis, the difference between the target value and all values below the target will be calculated. For minimization gap analysis, the difference between the target value and all values above the target will be calculated. |
Temporal Units | In DATAmaestro, you can choose between Unix time (ms) and (s) and Excel time. |
Timeshift tags | It creates, for each variable, a new variable which is offset in time compared to the original variable(s). The window is specified with lower and upper bounds and a step size. |
Train/Test split (Cross-validation) | It splits the learning set into a learning set and validation set. The model trains on the former reduced learning set and is evaluated on the latter. This method uses only one model to assess the error of a combination of parameters. It is the fastest method for cross-validation however performance may be degraded on small datasets. |
Test fraction (Cross-validation) | Split fraction used by the Train/Test split strategy cross-validation. It defines the fraction of records that should be extracted from the learning set where the remaining records make up the validation set. |
UCL variable (SPC) | It defines the upper control limit (UCL) below this value the process is considered to be under normal control. Graphically, the UCL is represented by a horizontal line below the average. |
Union (Record set) | It allows the combination of existing record sets. When combining two (or more) record sets using union, this is equivalent to keeping data points that are in both record set 1 “Or” record set 2. |
Unix time | Unix time is a system for describing a point in time. It is a number in seconds that have passed since 00:00:00 Thursday, 1st January 1970, Coordinated Universal Time (UTC), minus one second adjustment. Every day is treated as if it contains exactly 86400 seconds, so leap seconds are to be subtracted since the epoch (date and time from which a computer measures system time. Unix time can be in seconds and milliseconds. For more information, please check Unix Time. |
Unsupervised learning | Machine learning task with a set of inputs only (no output). Unsupervised learning algorithms seek to infer a structure or pattern between the different inputs. The most important method of unsupervised learning is Clustering. |
Upper shift (shifted variables) | Specifies the upper (time) bound of the window. An upper shift of 1 would create an additional variable in the data set that has its rows shifted up one line compared to the original variable. |
Utf-8 | It stands for Unicode (Universal Character Set) Transformation Format - 8 bits. It is a multibyte character coding and is basically used for almost all Worldwide alphabets. Could be specified by the user when a CSV is uploaded in DmA. |
Variable (formerly known as Attribute) | A variable is a property or characteristic of a record (for example, the weight of a mechanical piece, the time at which an event occurred or the eye color of a person) that varies from record to record. numerical: its value is an integer or real number. Such values can obviously be numerically ordered and compared. symbolic: its value is a string or symbol. It is qualitative and generally cannot be ordered (except for symbolic variables such that low/medium/high implying an intuitive order).
Candidate variables: the subset of variables which are being used as potential input variables for learning. Test variables: the subset of candidate variables which are finally retained in the modelling rules. Explicit variables: the set of variables which are explicitly stored in the database. |
Variable prefix | When a function or method creates additional variables, the new variable names will begin with the Variable Prefix. |
Variable set (formerly Attribute set) | User defined group of variables, often used as inputs to a modelling technique. |
Window left | It specifies left size of the window for the moving average or the number of previous rows to include in the moving average calculation for each given record. |
Window right | It specifies right size of the window for the moving average or the number of next rows to include in the moving average calculation for each given record. |
Weight variable (Decision tree based models) | Initial weight used to build tree models. It is a variable that contains the weights of the corresponding records. High values of weight are meant to give more importance to an record in the learning phase of the model. |
Weight decay (ANN) | During training, after each update, the weights are decreased by a small amount, a factor smaller than 1 and greater than zero (default: 0.5). |